Depois de ver algumas implementações onde os desenvolvedores utilizaram algorítimo de Hash para anonimizar IPs (sobre o qual escrevi esse outro artigo alertando), decidi extrapolar para o caso de Hash de CPF para deixar esse alerta.
O CPF é tido como informação sensível pela LGPD e é necessário pedir consentimento do usuário antes de armazenar essa informação ou então tomar medidas preventivas de controle de acesso e compartilhamento do mesmo.
Uma alternativa para não depender do consentimento é anonimizar o CPF para algumas funções, como compartilhamento com outros sistemas ou terceiros.
Como anonimizar, a legislação diz que não pode ser identificável o cliente final, ou seja, se o CPF 123.456.789-00 pertencer ao Fulano da Silva, uma função não poderia simplesmente transformar o CPF no número 987-654-321 que seria facilmente reversível ao número original.
Uma função Hash se comporta mais ou menos dessa forma, recebe uma palavra na entrada, nesse exemplo o CPF e calcula uma sequência a partir da mesma, normalmente representada em formato hexadecimal.
Clique e saiba Como funciona um algorítimo de Hash e como evitar ataques em sistemas
A primeira prerrogativa da função Hash é que, a partir do resultado obtido, não é possível se obter “facilmente” o valor de entrada, ênfase no facilmente.
Vamos exemplificar uma função Hash de CPF, que substitui os números por letras arbitrárias (1 sempre será X, 2 sempre será R, assim por diante).
Dado o CPF 123.456.789 (vou desconsiderar os dígitos verificadores, pois como o nome diz, são apenas dígitos verificadores, é possível calculá-los tendo os demais dígitos), temos a seguinte função e resultado Hash:
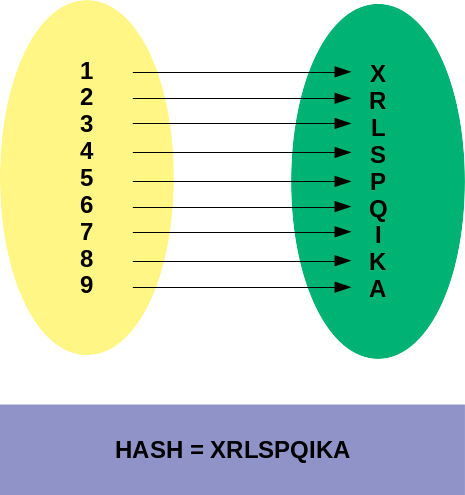
Exemplo simplificado de Algorítimo Hash (não utilizar em produção)
Alguém que quiser reverter esse algorítimo basta enviar um CPF 111.111.111 e verá que o resultado é XXX.XXX.XXX, logo irá concluir que o número 1 é substituído pela letra X, fazendo a mesma coisa para os demais números, conseguirá reverter o mesmo.
A segunda prerrogativa de algorítimos de Hash é que, dada uma entrada, a saída calculada é sempre a mesma, por exemplo, o Hash SHA1 do CPF 123.456.789 sempre será: 2b358614ea3fe92253f717c92d5cdf319dabea20, não importa quantas vezes usamos ele, conforme expliquei nesse outro artigo.
Bom, voltando ao problema original, o que vimos implementado foram ferramentas calculando o Hash do IP e armazenando em uma tabela. O alerta é que não faça isso, muito menos com CPF!
O problema é que o espaço de numeração de CPF é limitado em termos computacionais, são apenas 9 dígitos, o que daria 1 bilhão de combinações.
Na prática, é possível reverter um Hash armazenado para o CPF original em no máximo algumas horas utilizando um ataque de dicionário (dizemos ataque de dicionário pois conhecemos previamente todas as combinações possíveis de CPFs, esse é nosso “dicionário” para cálculo).
Se é reversível, não é anonimizado, então não está conforme com a LGPD.
Algumas horas para reverter um CPF pode ser um pouco demais, então vamos evoluir a forma do ataque:
Ataque com Rainbow Tables contra Hash de CPF
Rainbow Tables são tabelas de Hash pré-calculadas, elas servem para efetuar ataques de dicionário de forma mais rápida.
Para nosso caso, devemos calcular os Hashs de todos os CPFs possíveis (de 000.000.000 à 999.999.999) e deixar isso pré-calculado e armazenado.
São armazenados então com o Hash ordenado, ou seja, uma Rainbow Table dos CPFs de 1.1.1.1 a 1.1.1.9 se parecerá com a tabela abaixo, veja que os Hashs estão em ordem alfabética:
0c15c8cf315abdbf5b2fb7a46bd0c8346b90c0bf 1.1.1.5 25a7bff7461c09fe8044f0286e1e2de001a038d0 1.1.1.3 585dc63758547085df9f5baf08e545711755c377 1.1.1.4 7248b53f32a97ee66e1e74950e28e8787577e91f 1.1.1.2 955777f0e4c4d0f1e248ab9293b779c883eb5b79 1.1.1.7 9b94beeb7c155b78dba03fdec7467cedb6026c9e 1.1.1.1 d4dfcdd151e331cdbfcea5b11dd9bb0252e387d0 1.1.1.9 e66f2d7f116b90672833b2d2ebb1f4ab105529af 1.1.1.8 e8f374b31b0de7f706fb01fd525d9778108f7416 1.1.1.6
Ou seja, dado o hash 25a7bff7461c09fe8044f0286e1e2de001a038d0, rapidamente encontraríamos o CPF número 1.1.1.3 que originou o mesmo.
Isso pode ser armazenado em um banco de dados com índice para busca mais rápida, ou criado um banco de dados específico (digamos, usando árvore binária) para maior performance e menor espaço de armazenamento.
Lembrando que o CPF pode ser armazenado em 32 bitis com um pouco de otimização e um Hash de SHA1 tem apenas 160 bits, precisamos de 192 bits, ou 24 bytes para cada registro.
Considerando toda a numeração de CPF de 1 bilhões de números, precisamos de cerca de 24 Gbytes para armazenar toda a faixa em SHA1. Se usarmos alguns bytes de controle e uso do índice podemos chegar a cerca de 30Gb em disco usando um SGBD comum.
Um SGBD comum faria essa consulta em alguns mili segundos, ou seja, se alguém tiver acesso ao banco de dados onde os CPFs estão “anonimizados” com Hash, é possível reverter todos os CPFs de volta aos números originais com poucos recursos computacionais.
Isso posto, não podemos considerar de forma nenhuma que o Hash de um CPF é anonimizar um CPF.
Se é reversível, não é anônimo e não está conforme a LGPD
Igualmente para outros documentos sensíveis, como RG, SSN (Social Security Number), Telefones, Cidades, e até o Nome (se estiver separado em Nome e Sobrenome) todos dentro de um intervalo conhecido e previsíveis, são sensíveis a ataques de dicionário e de rainbow tables.
Se você precisa armazenar e compartilhar esses dados, considere utilizar criptografia comum com chave simétrica ou Tokenização, pelo menos ninguém irá confundir acreditando que o dado está em sigilo quando não está.
Se você precisar anonimizar de verdade esses dados, considere outros métodos como Data Blurring ou Masking, onde removemos uma parte do número, por exemplo, o CPF de exemplo ficaria 123.***.**9, sem os dígitos verificadores, a única forma de completar a informação é adivinhar os dígitos faltantes.
Referências e outras leituras:



2 Comentários
Então podemos salvar um hash do CPF + Nome Completo, já que esse espaço de randomização será imenso, correto?
Hum, depende… você capturou o nome para alguma coisa, imagino que vai armazenar ele em aberto em outro campo.
Alguém que ver um campo chamado CPF_HASH na base e o resultado pode não saber a princípio como chegou naquele resultado, mas alguém olhando o código vai saber (digamos, em uma auditoria de LGPD), ou mesmo numa auditoria GREY BOX (onde se testam vários valores e se olha o resultado na base de dados).
Sabendo como funciona, a dificuldade computacional para reverter Hash(Nome+CPF) é praticamente a mesma que Hash(CPF), o campo de entrada é maior, mas o campo de saída é limitado e as variações de CPF são extremamente limitadas, em algumas horas reverte o CPF.
Melhora um pouco em relação às rainbow tables, mas aí valeria a pena usar Salt de uma vez que é mais aleatório do que o nome e você já tem funções prontas pra isso. O problema continua o mesmo, em algumas horas reverte o CPF, mas pelo menos são algumas horas para cada CPF.
Se você procura adequação à LGPD, lembre-se que pedir e armazenar CPF em algumas situações é permitido (emissão de Nota Fiscal por exemplo), você também pode solicitar permissão pro usuário, havendo alguns controles de segurança está tudo certo.
Se quer armazenar o CPF de forma protegida na base como medida de proteção, considere algum algorítimo reversível mesmo, como AES e guarde bem a chave (fora do banco, pode ser até fixa dentro do código).