Artigo atualizado em 22/05/2020
Uma palavra já corriqueira nos projetos de TI são IOPS, e embora alguns fornecedores já comecem a medir e considerar nos projetos, nem sempre são entendidos e calculados corretamente.
O que significa IOPS?
IOPS é uma abreviação para Input/Output per Second, ou operações de entrada e saída por segundo, é utilizado para medir performance em dispositivos de armazenamento, como drives de discos, drives SSD e Storages.
Sua importância para os projetos de TI é que ele indica quantas operações de leitura e escrita o dispositivo é capaz de realizar por segundo e essa quantidade impacta diretamente na performance das aplicações.
Novos HDDs (Hard Disk Drives, ou discos rígidos) tem sido vendidos com cada vez mais capacidade de armazenamento e podem dar a sensação de que precisamos ter menos quantidade de HDs para compor uma solução, pois podemos obter mais espaço em disco com menos drives físicos.
Mas um determinado ambiente precisa de uma determinada performance e só é possível alcançar a performance adicionando a quantidade de discos adequada, daí a importância de saber quantos IOPS são necessários para executar em um ambiente, principalmente em Datacenters e ambientes virtualizados.

O problema em si: leis da física
O problema de performance dos drives de disco se dá por limitações físicas mesmo, veja o exemplo da figura abaixo, onde o HDD girando no sentido horário precisa ler as informações localizadas nos pontos 1, 2 e 3.
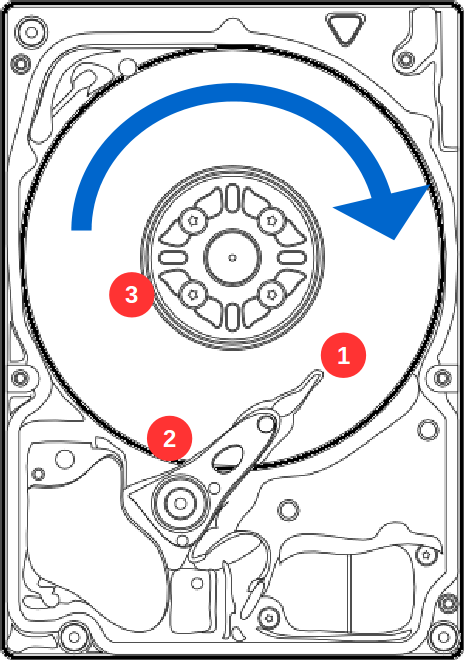
Leitura aleatória, operação normal em um HDD
Para fazer a leitura nessa sequência, o HDD precisa dar quase uma volta inteira para ler cada bloco. Considerando um HDD que trabalha a 7200 RPM (rotações por minuto), uma volta demora cerca de 8,3ms, esse é o tempo mínimo entre essas leituras, o que permitiria até 120 leituras por segundo.
Só que, como o bloco 2 é em um extremo do HDD e o bloco 3 é em outro extremo, pode ser que a cabeça de leitura não se movimente rápido o suficiente para ler o bloco 3, o que obriga a cabeça a esperar por mais uma volta do disco para fazer a leitura do dado, reduzindo a capacidade de leituras por segundo.
Assim, o cálculo de IOPS de um disco é dado pela fórmula:
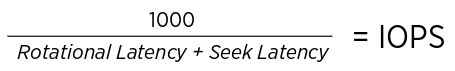
Onde Rotational Latency é o tempo de espera até o disco girar onde precisamos ler o dado, e Seek Latency é o tempo de deslocamento da cabeça de leitura até o ponto no HD.
Divide-se mil pelo número para calcular os IOPS, então, em um HDD comum de 7.200 RPMS que tem Rotational Latency de 8,3ms e Seek Latency de 5ms, a conta fica: 1000 / (5+8,3), podemos dizer que conseguimos 75 IOPS.
Claro que, numa situação ideal de leitura, onde os dados estão alinhados na sequência, as latências de rotação e de procura diminuem, aumentando a capacidade de leitura dos HDDs, mas isso só é possível em situações bem particulares, com um HDD sendo acessado por uma única aplicação que tenha os dados alinhados corretamente, o que raramente acontece em um ambiente comum, seria como no exemplo abaixo:
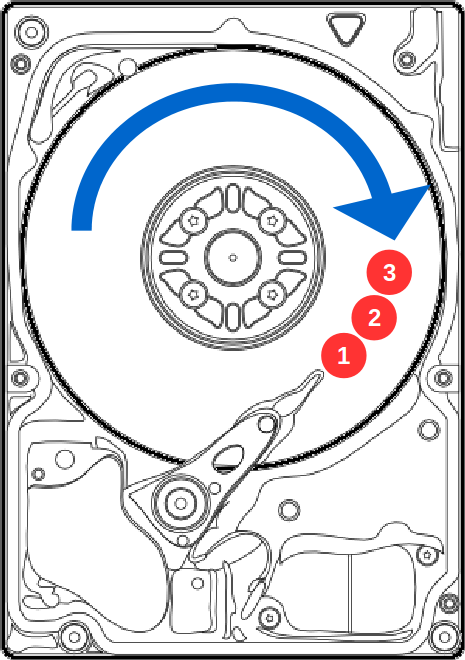
HD em leitura sequencial
Para não dizer que é praticamente impossível, essa situação acontece com frequência em discos que são usados para backups em estratégias D2D2T, mas com o tempo de uso, esses discos acabam ficando fragmentados, e boa parte da eficiência se perde.
Ainda é possível que o disco “force” essa situação alinhando algumas leituras, em uma operação chamada Command Queue, onde o HDD recebe muito mais requisições do que é capaz de entregar em um período, o controlador pode reordenar os comandos de leitura e gravação para se alinharem com a rotação do HDD e ter a melhor performance possível.
Leia mais sobre isso em Native Command Queue (em inglês) ou em Tagged Command Queue (em inglês).
Tirando isso, vamos ver outras possíveis soluções para melhorar a performance dos discos:
Solução 1: discos que giram mais rápidos
Uma alternativa para fazer essa leitura mais rápida é acelerar a velocidade dos discos. Diminuindo o tempo de rotação, o disco chega mais rápido no ponto de leitura.
Discos de 15000 RPMs são mais rápidos que discos de 10000 RPMs ou 7200 RPMs, pois diminuímos o Rotational Latency conforme a tabela abaixo:
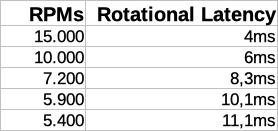
Valores aproximados
Experimentos feitos a 20.000 RPMs indicaram que os discos seriam mais sensíveis a vibrações, podendo apresentar defeitos mais facilmente, além de consumir mais energia elétrica e aquecer mais.
Outro fator contra acelerar os discos é que limitaria a capacidade, quanto mais rápido a rotação, menor a densidade de trilhas por polegada. Para se ter ideia, um disco de 2Tb tem 236000 trilhas por polegada.
Solução 2: diminuindo o tamanho físico dos discos
Trabalhando com discos menores, a cabeça de leitura precisa se movimentar menos, diminuindo o Seek Time.
Por isso, discos de 2,5″ são ligeiramente mais rápidos do que discos de 3,5″ com a mesma capacidade, pois a cabeça precisa movimentar menos para passar por toda a área útil do disco, trazendo um ganho de 20% a 30%.
No início da era PC, os Desktops eram vendidos com discos de 5″, embora mais baratos para fabricar, eram extremamente lentos.
Solução 3: duas cabeças pensam melhor do que uma
Uma alternativa para diminuir o Seek Time seria acrescentar duas ou mais cabeças de leituras independentes, como já até existe patente para isso (em inglês) propriedade da Seagate e existiram drives assim no passado, mas os custos de fabricação são maiores, o espaço para o disco em si é menor (resultando em menos capacidade), consume mais energia elétrica e gera mais calor.
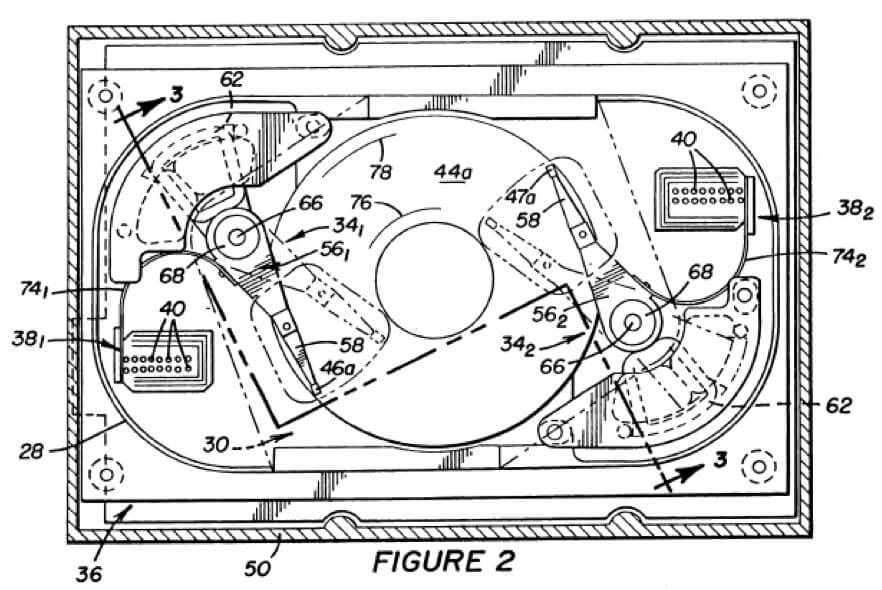
Dual Head Hard Drive
Com duas cabeças de leitura ocorre um ganho de até o dobro de IOPS para a mesma capacidade e rotação de disco, pois o tempo de rotação pode ser cortado pela metade (já que cada cabeça está em um lado do disco) e a capacidade de deslocamento da cabeça é o dobro, pois existem duas.
Outra possibilidade seria implementar dois leitores na mesma cabeça, isso reduziria o Seek Time pela metade, a cabeça teria que movimentar apenas metade do percurso, diminuindo o consumo de energia e gerando ganhos de IOPS de até 50%.
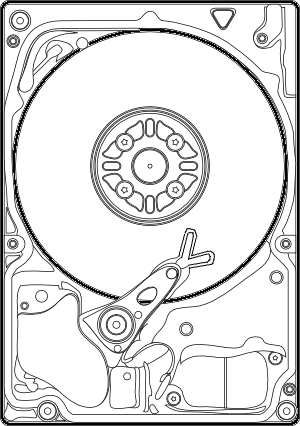
Alien HDD
Como nenhuma dessas soluções são cogitadas hoje pelos fabricantes, ficamos com as outras soluções.
Solução 4: discos com maior capacidade
Discos com maior capacidade (600Gb versus 146Gb por exemplo) podem ser mais rápidos quando usados com a mesma quantidade de dados, pois oferecem maior densidade de dados por polegada.
Depois de uma migração, por exemplo, se tiver 100Gb no servidor antigo com discos de 146Gb, ao migrar para um servidor novo com discos de 600Gb, os mesmos 100Gb estarão posicionados no início do HD, exigindo muito menos movimentação da cabeça de leitura, como pode ser observado na figura abaixo:
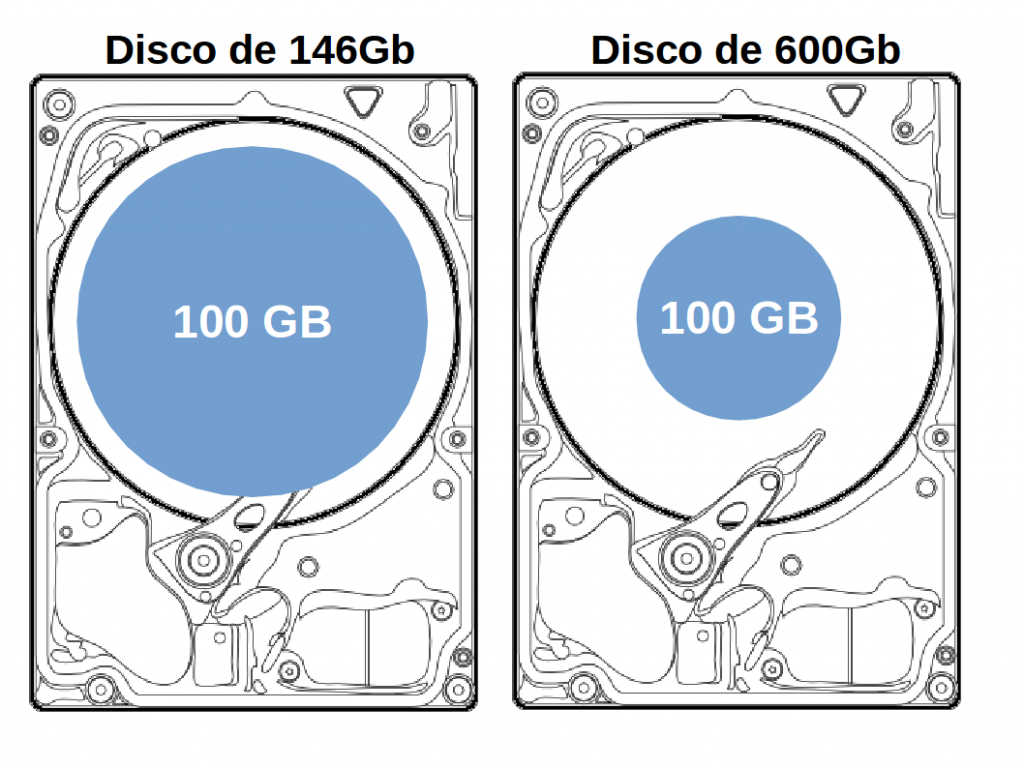
Exemplo de 100Gb ocupando um disco de 146Gb e os mesmos 100Gb ocupando um disco de 600Gb
Isso também explica porque depois de uma desfragmentação do disco, a performance melhora significativamente, o processo de desfragmentação move os arquivos para o início do disco, e tenta deixá-los em uma linha contínua, o que melhora a leitura.
Embora factível, não gostaríamos de investir em discos de 600Gb para utilizar apenas 100Gb, então não é uma solução viável economicamente.
Solução 5: Cache
Muitos fabricantes de drives incluem uma certa quantidade de memória Cache no drive, isso permite, por exemplo, que, se for solicitado a leitura de um dado recém gravado ou a leitura do mesmo bloco em um curto intervalo de tempo, esse dado possa ser entregue da memória cache ao invés de ter que esperar a leitura do disco físico.
Alguns fabricantes até incluem uma funcionalidade chamada Read Ahead ou Seek Ahead, onde a cabeça de leitura lê o bloco de dados solicitado, e, já que o disco está rodando, lê o próximo bloco de dados subsequente e coloca no Cache, assim, se estiver ocorrendo uma leitura contínua de dados, é possível ao HDD entregar muito mais rápido.
Mas a quantidade de memória Cache nos HDDs é mínima, chegando a 256Mb em drives modernos, o que faz com que a probabilidade do Cache ter a informação necessária, comparado com as centenas de GBs do disco ser mínima.
Ainda em sistemas operacionais modernos também são implementados Cache, utilizando memória física, e com um processo similar ao implementado no HDD, alivia bastante.
Mas esse processo requer que tenhamos bastante memória livre (sem estar em uso pelos aplicativos), e em um exemplo comum, 2GB de memória do computador tem pouca chance de ter em Cache os dados de 500GB de um HD.
Esse Cache pode ser percebido em algumas situações simples, por exemplo, em um computador comum, ao abrir um aplicativo, digamos, o Word, fechando o mesmo e abrindo novamente depois de alguns segundos, na segunda vez abrirá muito mais rápido se houver memória sendo usada para Cache suficiente.
Leia mais sobre Cache nesse artigo (em inglês).
Solução 6: Discos SSD
Mais memória nos servidores ou mais cache nos HDDs não resolvem a limitação física dos drives de disco (HDD ou Hard Disk Drives), por isso muitos fabricantes tem incluído SSD (Solid State Drives) nas soluções para atingir a performance necessária pelas aplicações.
Para comparação, esses são os números de IOPS médios dos HDDs de mercado:
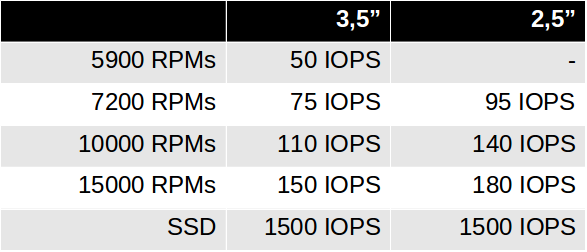
IOPS por tipo de disco
Pode-se observar que os discos mecânicos, por mais rápidos que sejam, não chegam nem perto dos drives SSD em quantidade de IOPS.
Mas os drives SSD também são bem mais caros por GB, então, uma solução ideal deve incluir discos SSD e HDD para balancear entre custo de aquisição, espaço disponível e performance.
A solução ideal também deve incluir software inteligente o suficiente para mover os dados mais acessados para os discos mais rápidos e os dados menos acessados para os discos de maior capacidade.
Solução 7: RAID
Podemos somar a performance de vários discos usando RAID (Redundant Array of Independent Disks).
Por exemplo, com RAID 0 (zero) em dois discos de 7200 RPMs, os dados são distribuídos em ambos os discos por igual, isso permite atingir a velocidade de até 150 IOPS, que seria alcançada apenas com um disco de 15000 RPMs e o custo de aquisição para a mesma quantidade de espaço pode ser menor usando discos de 7200 RPMs.
Claro que não recomendamos usar RAID 0 numa aplicação crítica, mas RAID 5 ou RAID 10 são perfeitamente aceitáveis, obtendo um nível de segurança e performance adequados. Para exemplificar, calculamos abaixo 2 cenários semelhantes com RAIDs e tipos de discos diferentes:
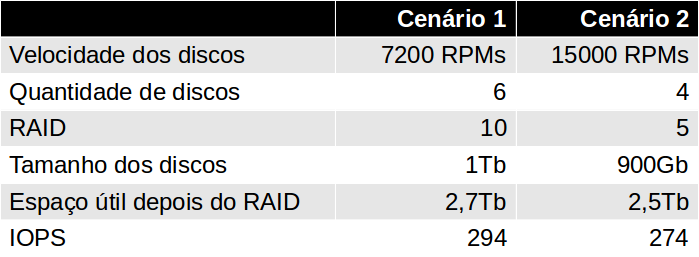
Os dois cenários apresentados são bem parecidos em espaço disponível e performance, mas a chance é que o cenário 1 com 6 discos de 7200 RPMs tenha um preço bem mais acessível do que o cenário 2 com 4 discos de 15000 RPMs.
Existem outros fatores a serem considerados, 6 discos consomem mais energia, geram mais calor e tem maior probabilidade de quebra do que 4 discos, mas o RAID 10 utilizado é mais seguro.
Em um projeto de poucos servidores o cenário 1 é sem dúvida mais vantajoso, já em um projeto com dezenas de servidores, o cenário 2 deve ser considerado pelos outros ganhos em eficiência.
IOPS em ambientes de Nuvem
Mesmo em ambientes de Nuvem, as limitações físicas dos discos ainda existem, ainda que discos SSD estejam se tornando mais comuns, é normal que parte do armazenamento seja feita em discos rígidos comuns ou que limitações sejam aplicadas.
Na Amazon AWS por exemplo, ao utilizar o armazenamento EBS (Elastic Block Storage) para rodar as máquinas virtuais, o tipo padrão de disco é GP2 (General Purpose SSD).
Esses discos tem por padrão 100 IOPS disponíveis para discos até 33Gb, ou 3 IOPS para cada GB acima disso. Isso significa que um disco de 100Gb tem reservado 300 IOPS.
Comparando com discos físicos, 100 IOPS é mais ou menos o que temos em um discos de 7.200 RPMS de 2,5″, é bem pouco para um disco SSD, e também é bem lento para rodar um banco de dados ou aplicação que faz muitas operações de disco.
Claro que, ao aumentar o tamanho do disco, aumentamos os IOPS reservados, e a AWS também oferece o tipo de disco IO1 (Provisioned IOPS SSD), onde é possível especificar quantos IOPS são requeridos para aplicação, mas isso tudo é tarifado a parte, podendo multiplicar por várias vezes o custo de discos.
Para dar performance adequada, a AWS oferece para discos GP2 o uso de até 3.000 IOPS em momentos de pico, mas limitado em uma quantidade de “créditos”.
Isso significa que sua aplicação pode, em uma SQL mais pesada por exemplo, atingir até 3.000 IOPS, o que é bem rápido, mas você terá uma quantidade de tempo que pode rodar essa consulta. Se essa consulta rodar por muitos tempo (cerca de 30 minutos), seus “créditos” de burst terminam e a performance do disco volta a ser limitada em 100 IOPS (ou mais, dependendo do tamanho do disco).
Você pode aprender mais sobre como monitorar isso nesse artigo (em inglês) e ver uma explicação melhor nesse artigo (em inglês).
Quantos IOPS preciso no meu projeto?
Essa é a pergunta chave. O ideal é que o fornecedor do sistema informe quantos IOPS são necessários por usuário conectado no sistema, daí você pode fazer a projeção de crescimento e calcular os IOPS necessários no ambiente.
Mas o mesmo sistema rodando em empresas similares, pode ter comportamentos diferentes por pequenas alterações no uso, e, na prática, poucos fornecedores de sistemas estão prontos para medir e recomendar essa informação.
Então, a melhor forma é medir a quantidade de IOPS utilizado no ambiente já existente e fazer o projeto baseado nessa análise.
É possível utilizar ferramentas do próprio sistema operacional, no Windows basta usar o Performance Monitor, e no Linux usando um utilitário como o iotop.
Depois de saber quantos IOPS são necessários, basta fazer o cálculo de quantos discos são necessários e utilizando qual nível de RAID.
Ou mesmo, montar uma solução mista, com discos sólidos e discos rígidos, mantendo dados mais acessados nos discos mais rápidos e dados menos acessados nos discos mais baratos, mas isso requer tecnologias de Storage e Tierização, a serem tratados em outro artigo.
Artigo publicado originalmente no blog da Sky Monitor




12 Comentários
Excelente artigo!
Parabéns, total abordagem sobre o tema.
Informação extremamente importante. Muito bom o artigo.
Parabéns!
Muito bom o artigo.
Artigo muito bom e de extrema importância.
Pingback: Dica: Entenda Virtualização, com 1 post e alguns vídeos. | Virgilio Pontes
Parabéns Fernando!! Excelente artigo!!
Gostei muito da matéria. Gostaria receber mais informações sobre o sistema RAID.
Excelente artigo.
Excelente este matéria.
Excelente artigo, parabéns!
Excelente!